Je nám ctí Vám oznámit, že v čase předvánočním se podařilo dobrovolníkům sesbírat a ověřit posledních několik potřebných vět, a dokončit plnou lokalizaci stránky projektu Mozilla Common Voice, a tento je tak k dnešnímu dni již v plném provozu pro sběr nahrávek hlasu v českém jazyce.
Projekt Common Voice je iniciativa Mozilly, která pomáhá strojům učit se, jak mluví skuteční lidé.
Jenom pro připomenutí, co je to projekt Common Voice? Citováno z oficiální
stránky projektu Common Voice, „Projekt Common Voice je iniciativa Mozilly, která pomáhá strojům učit se, jak mluví skuteční lidé.“ Ve zkratce, projekt Common Voice vytváří databázi hlasových nahrávek zveřejňovanou pod tou nejsvobodnější licencí, to jest jako volné dílo. Tyto nahrávky sbírá od všech možných dobrovolníků, jako jste například i Vy nebo já, a dává je k dispozici komukoliv na jakékoliv použití, typicky například různé projekty strojového učení. Na rozdíl od některých podobných projektů se navíc nesnaží získat perfektně čisté nahrávky hlasu, ale spíše se orientuje na nahrávky takříkajíc z reálného života, kde lidé mluví na nekvalitní mikrofony v hlučném prostředí, a často navíc ještě z opačného konce místnosti. Tímto a svou otevřeností se tedy jedná o vskutku ojedinělý projekt.

Co tedy udělat, když se chcete také zapojit do tvorby databáze projektu Common Voice? Nejjednodušší, co můžete udělat, je prostě zamířit na stránky projektu Common Voice a začít číst nahlas věty tam nabízené. Nestrachujte se přitom o kvalitu svého mikrofonu nebo hlučnost svého okolí. Nízká kvalita záznamu není vůbec na škodu, a v podstatě jediné podmínky, které musíte splňovat, je, že zadané věty přečtete správně, v nahrávce půjde alespoň nějak rozpoznat, co říkáte, a na pozadí nebude nikde slyšet hlas nějaké jiné osoby, u kterého by šlo také rozpoznat, co říká. Navíc se ani nebojte, že byste měli na nahrávání málo času; nahrání jedné sady vět Vám zabere v průměru přibližně 30 sekund.
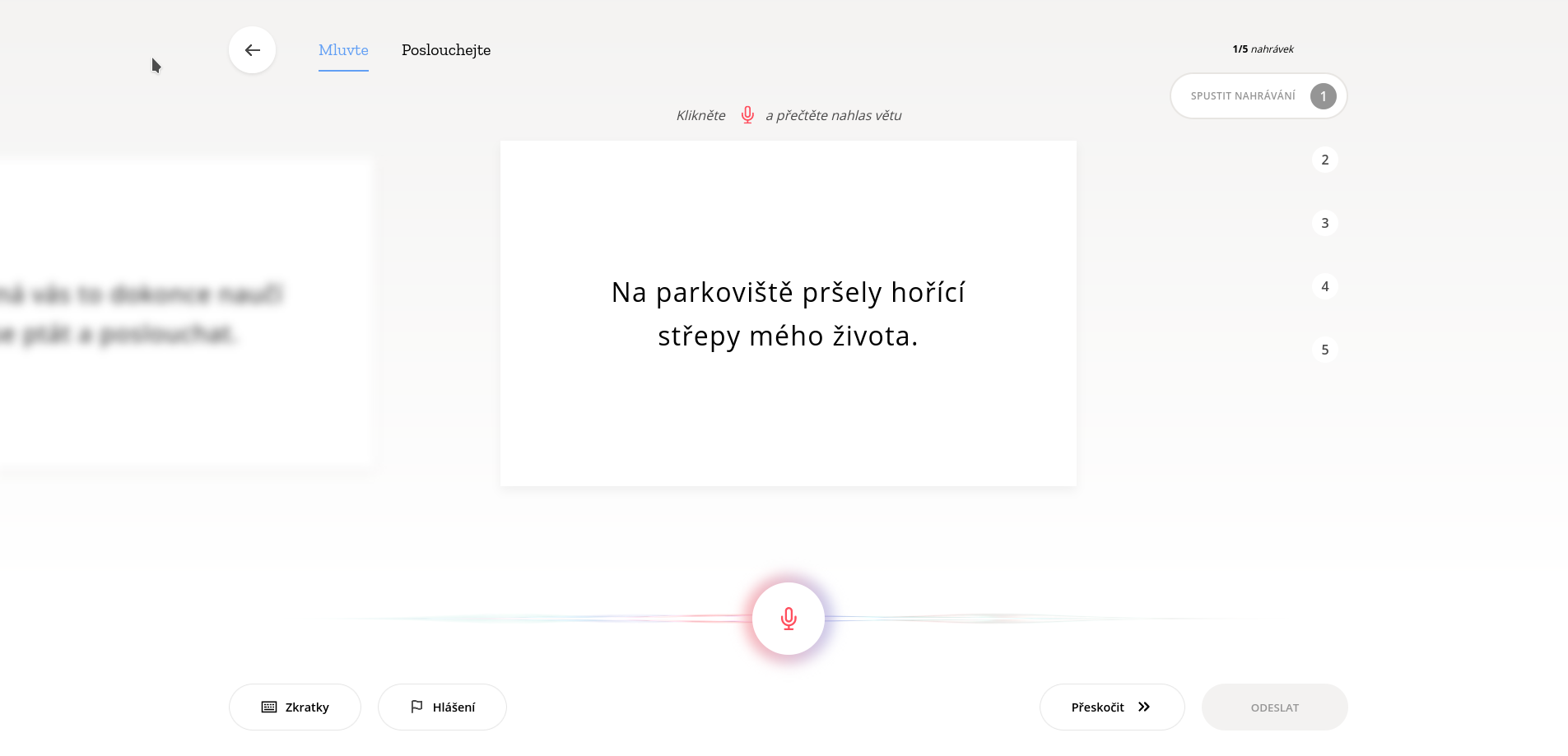
Pokud nechcete nebo nemůžete nahrávat, další možností je poté poslech a kontrola klipů již nahraných jinými. Z důvodů zajištění kvality dat v databázi totiž musí být u každé individuální nahrávky minimálně dvěma uživateli ověřena její přesnost. Toto pomáhá zabránit případům, kdy by kupříkladu uživatel kvůli přehlédnutí přečetl něco trochu jiného než je napsáno, či pomáhá bojovat proti různým internetovým individuím, která by se mohla pokoušet zanést do databáze místo zadaných textů různé vulgarismy.
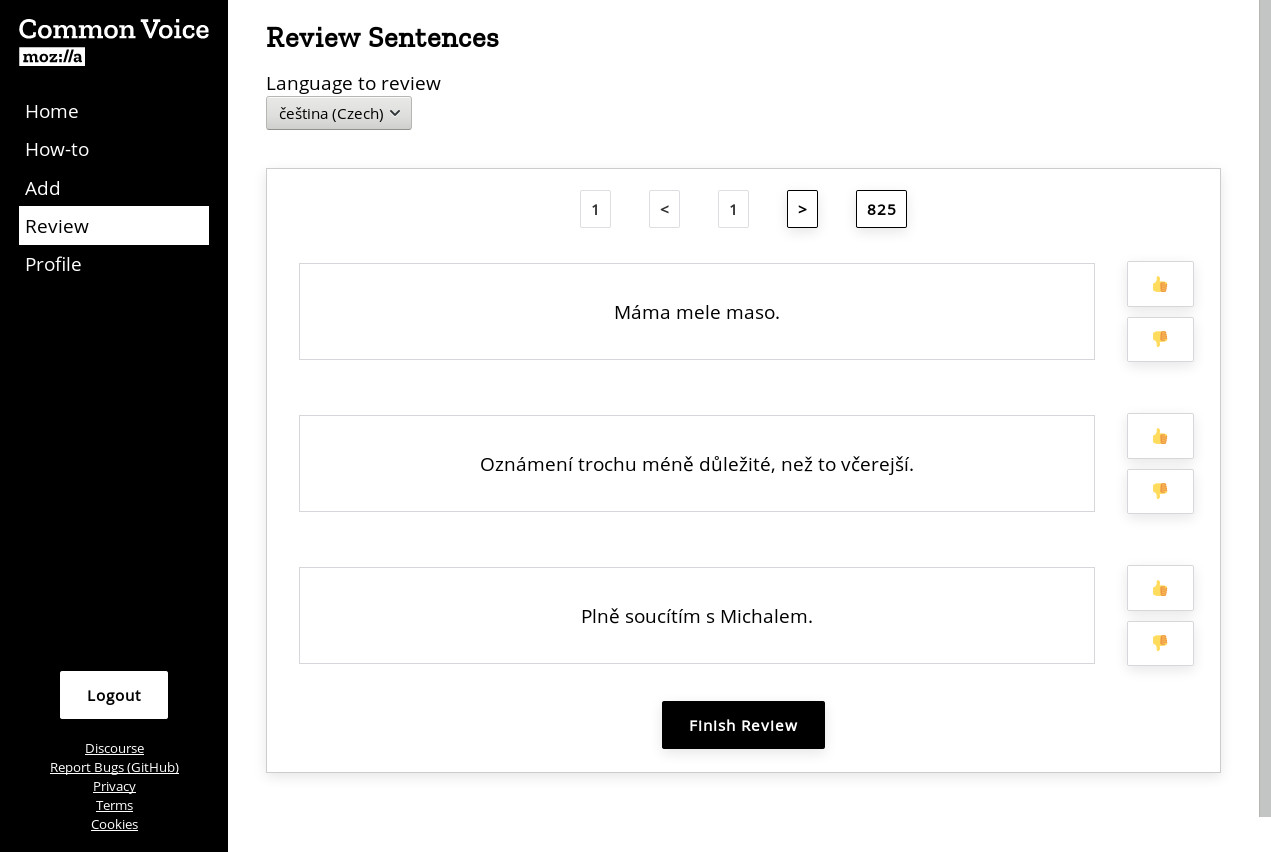
V neposlední řadě pak můžete pomoci se sběrem textů ke čtení v rámci projektu Common Voice, a to na stránce nástroje pro sběr vět projektu Common Voice, opět ať už získáváním samotných vět do databáze z různých zdrojů, nebo jejich manuální kontrolou. Ačkoliv jsme již pro češtinu nasbírali dostatek vět, aby mohl být projekt Common Voice v češtině spuštěn, do budoucna jich přesto bude stále potřeba mnohem více.
Par otazek napsal(a)
napsal(a)
Jindřich Dítě napsal(a)
napsal(a)
Par otazek napsal(a)
napsal(a)
Jindřich Dítě napsal(a)
napsal(a)
Marcel Janeček napsal(a)
napsal(a)